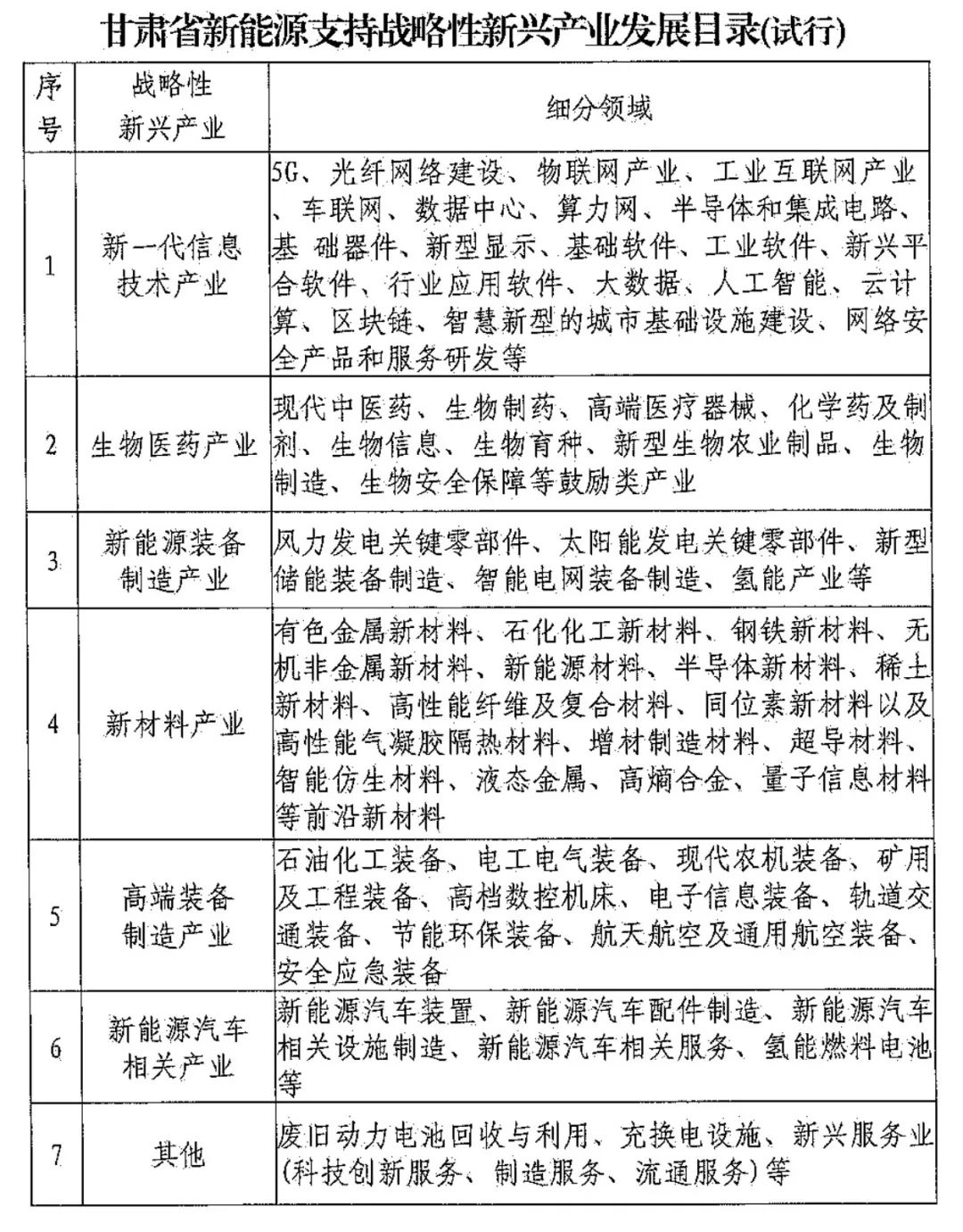
网讯:硬件打基础,布局上台阶。
在数字化浪潮的席卷之下,人工智能已成为推动时代前行的核心引擎。
图片智算中心已经成为满足大规模模型训练与推理需求的“生命线”。
随着AI的持续渗透与深化应用,算力需求如潮水般汹涌而至,传统计算架构面临前所未有的挑战,在此背景下,“万卡集群”作为新一代大模型竞赛的关键,正逐步成为智能计算领域的新常态,其发展也备受业界关注。
智算中心驶入快车道
硬件打基础,布局上台阶,智算中心作为集算力服务、数据服务和算法服务于一体的综合性平台,正在以前所未有的速度发展。
在实际应用中,智算中心已经成为满足大规模模型训练与推理需求的“生命线”。随着10亿参数规模以上的大模型数量突破百个,AI算力需求急剧增加。例如,OpenAI训练GPT-4模型时使用了2.5万张英伟达A100 GPU,这种大规模的算力需求推动了智算中心向更高性能、更大规模的方向发展。
近年来,政府对于智算中心建设的重视程度不断提升,通过出台《新型数据中心发展三年行动计划(2021-2023年)》《“十四五”国家信息化规划》《“十四五”数字经济发展规划》等一系列政策,为智算中心的发展提供了坚实的政策保障。数据显示,截至2023年底,全国名称中带有“智算中心”的项目已达128个,仅2023年全年,全国建成或者正在建设的智算中心有20多座,且这一数字在2024年继续快速增长。
智算中心的技术特点主要体现在其高性能计算能力和高效的资源整合上。随着大模型训练与推理需求的爆发,尤其是GPU供应紧张,算力需求增长远超单颗AI芯片性能的增长速度。
通过集群互联弥补单卡性能不足,成为解决AI算力荒的必要路径。千卡集群和万卡集群是满足AI算力需求的抓手,特别是在未来几年内,通用算力和智能算力的快速增长将推动智算中心的建设和发展,通过整合高性能GPU计算、RDMA网络、并行文件存储和智算平台等关键技术,构建了一台“超级计算机”。
百舸争流构建新产业格局
事实上,面向智算中心从千卡集群到万卡集群的构建并非简单的GPU卡堆叠,而是一项高度复杂的超级系统工程,通过智算网络技术把上万块GPU芯片像“积木”一样拼接在一起,大幅提升GPU节点间的通信效率,使其在瞬息之间便能处理海量数据与复杂计算任务。
目前,业界主流的芯片主要是英伟达H100,近年来,随着部分国家对高端芯片的出口管制不断加强,国外厂商生产的高档GPU出口受到限制,使得我国在智算领域面临算力供应不足的风险。这种外部压力促使我国加快智算中心国产化的进程,以减少对国外芯片的依赖。近年来,国内已经涌现出了一些优秀的芯片厂商,如昇腾、寒武纪、百度等。
其中,华为昇腾910B是华为自主研发的AI芯片,采用了7纳米制程工艺,昇腾910代表了昇腾系列的最强算力,其半精度FP16算力达到了320TFLOPS,整数精度INT8算力更是高达640 TOPS。昇腾910配合华为开源的MindSpore框架,可以显著提高AI训练的效率。
寒武纪的思元370是采用7nm制程工艺,首款采用chiplet芯粒技术的AI芯片,就是在一颗芯片中封装2颗AI计算芯粒,每一个MLU-Die具备独立的AI计算单元。整体集成了390亿个晶体管,具有256TOPS(INT8)的最大算力。
昆仑芯2采用7nm制程,搭载昆仑芯自研的新一代XPU-R架构,是国内首款采用GDDR6显存的通用AI芯片,相比昆仑芯1代,昆仑芯2的整数精度(INT8)算力达到256 TeraOPS,半精度(FP16)为128 TeraFLOPS,而最大功耗仅为120W,昆仑芯2高度集成了ARM CPU算力,并支持硬件虚拟化、芯片间互联、视频编解码等功能。同时,它还支持C和C++编程,可编程性国内领先、对标全球业界最先进水平。
含光800是阿里巴巴旗下半导体公司平头哥高性能AI芯片,含光800采用了自研的架构、基于达摩院的算法和阿里巴巴的场景,由台积电7nm工艺打造,在业界标准的ResNet-50测试中推理场景性能达到78563IPS,经过公开测试比业界的其他AI芯片性能高4倍。
与此同时,随着国产芯片的异军突起,有关万卡集群的构建与兼容性挑战也浮出水面。
硬件方面,由于不同型号的GPU在性能、功耗、接口等方面存在差异,要求集群设计和部署时必须考虑硬件的兼容性。
随着GPU数量的增加,集群的扩展性、散热、能耗等问题也日益凸显,同时,不同厂商、不同版本的操作系统、驱动程序、深度学习框架等可能存在不兼容的情况。
例如,某些特定的深度学习框架可能只支持某些型号的GPU,或在某些操作系统上运行不稳定,最后则是由于生态的兴起,开源软件、商用软件的配套也需要得到不断完善。

从硬件到生态:推动AI产业可持续发展
宏观来看,随着全球科技竞争的加剧,构建自主可控的国产万卡系统,不仅关乎技术主权,更是推动AI产业持续健康发展的关键,其中生态的构建尤为复杂且至关重要。
今年三月,中国工程院院士郑纬民指出,尽管国产AI芯片与业界领先水平存在差距,但生态的完善能够有效弥补这一短板,确保大多数任务不会因芯片性能的微小差异而受显著影响。
事实上,面对英伟达CUDA生态的强势地位,国内AI生态链建设显得尤为迫切。英伟达凭借其完善的生态链,成为了全球AI大模型的首选算力供应商,甚至国内众多AI公司也不得不依赖其生态。相比之下,我国计算生态链尚在建设中。
因此,要打破封闭和垄断,首要任务是推动算力技术的开放与标准化。通过采用多元开放的架构,确保系统兼容主流软件生态,支持广泛的AI框架、算法模型及数据处理技术,从而降低应用迁移门槛,促进技术创新与应用的快速迭代。
同时,软硬件的深度融合是提升智算效能的关键。针对不同类型的GPU及其软件环境,进行细致的协同优化,包括驱动、框架、操作系统等各个层面,以实现性能的最大化和稳定性的提升。
最后,生态的构建需要整个产业链的共同努力。通过鼓励上下游企业的积极参与,推动算力技术的标准化、模块化,形成开放共享的技术生态。这不仅能够促进技术间的互联互通,还能加速资源的有效配置与利用。
构建国产万卡系统,虽然很难,但很必要。人工智能的模型研发、模型训练、模型精调、模型推理都需要算力,算力存在于大模型生命周期的每一环。
在智算领域,生态的构建是一场持久战,也是决定未来格局的关键,这不仅是技术层面的追赶,更是生态体系、创新机制与全球合作模式的重塑。只有如此,国产万卡系统才能真正成为推动中国乃至全球AI产业发展的强大引擎。